近年来,大语言模型受到了人们的广泛关注,例如 GPT-4o、LLaMA、Stable Diffusion 等。近期OpenAI 还发布了新模型 o1。
大规模预训练成为实现通用智能的、具有前景的途径之一。除了文本之外,多模态大模型(包括图像、音频、视频),是大模型最前沿的技术之一。
然而目前,学术界对于如何从仅包括文本-图像的预训练,到引入视频、音频具有四个模态预训练发展,还没有比较明确的解决方案。
发展大规模的图文音视频预训练,需要解决一系列挑战,例如多模态数据对齐、预训练范式和整体结构设计等。
从领域进展来看,此前,OpenAI 已开发多模态学习框架 CLIP,其通过大规模的图文配对数据进行训练,以学习视觉概念和文本描述之间的关联,并收集逾 4 亿个高质量的文本-图像对。
此外,Google 和 Meta 也分别开发了 SigLip 和 MetaCLIP。
然而,开发大规模的音视频预训练框架需要庞大的计算计算资源,学术界少有人研究,由于这一“深水区”里技术往往高度重要也极具商业价值,工业界对这部分的研究往往“三缄其口”。
其中,不可忽视的问题在于:
数据方面,图文与音频、视频或深度等多模态信息配对时,如何来收集数据并对其有效整合?
算法方面,多模态输入情况下,如何解决 Transformer 的计算效率?
香港中文大学和中国科学院等团队合作,受人脑从基础感知、认知到通用技能过程的启发,他们提出了一种名为多模态上下文(MiCo,Multimodal Context)的大规模全模态预训练范式。
它以人类学习知识的过程作为模型的通用训练思路,使 MiCo 能够在预训练过程中得以引入更多的模态、数据量和模型参数。
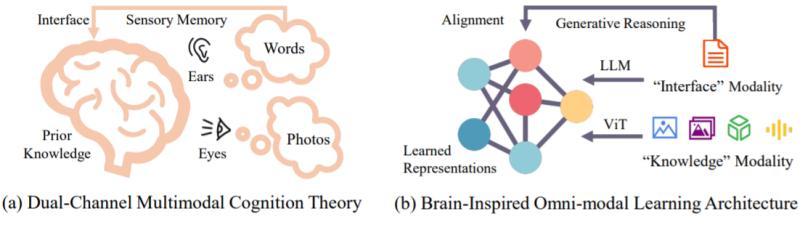
图丨大脑中的多模态认知过程启发了该研究中的设计(来源:arXiv)
基于 MiCo 预训练的模型在多模态学习中,表现出卓越的性能。
研究人员对 MiCo 进行了一系列测试,包括:10 种不同模态的单模态感知基准、25 种跨模态理解任务和 18 种多模态大模型基准。
结果显示,MiCo 共取得了 37 项最强性能(SOTA,State of the Art)的记录,与此同时,MiCo 全模态预训练的 1B 模型可以轻松超越图文预训练的 Intern-VL-6B 模型。
基本上可以认为 MiCo 是最强的开源预训练范式,涵盖最广泛数据模态,展示最强性能。
其通过大规模全模态预训练的模型可作为感知领域通用的编码模型,从而有望为多模态生成领域,提供一种更加合理、更加有效的评估量化指标。
日前,相关论文以《探索全模态预训练的局限性》(Explore the Limits of Omni-modal Pretraining at Scale)为题,发表在预印本网站 arXiv[1]。
香港中文大学博士生张懿元和中国科学院博士生李翰东是共同第一作者,中国科学院自动化所刘静教授担任通讯作者,香港中文大学岳翔宇教授是论文尾作。

图丨相关论文(来源:arXiv)
从人类感知和认识世界的过程来看,人眼能够看到连续的、持续的具有对应物理信息和物理规律的视频;耳朵能听到和解析对应的各种音频。
与此同时,人类将文字作为记录和传递信息的工具,并通过触摸、运动等能够对距离和形状具有天然的感知先验。
基于这些特性,得以学习和提升相关知识,从而逐渐具备各方面常识和通用技能。
AI 对于图片、音频等不同模态虽然能提供互补的信息,但由于具有模态的差异,基于通用框架让其对不同模态的理解充满挑战。

图丨全模态预训练(来源:arXiv)
研究人员将人类认知和认识世界的过程,“复刻”到对大模型的多模态训练中。
MiCo 通过构建多模态上下文,实现了不同模态之间的有效对齐和融合。这种上下文关系不仅增强了模型对单一模态数据的理解,还促进了跨模态的深入学习。
“我们将每种模态的特点与优势整体混合,来引导预训练模型,从而能够更清晰、更明确地理解不同类别信息之间的交互,以及其相互作用。最终,在整体上促进了对全模态的理解。”张懿元说。

图丨张懿元(来源:张懿元)
文本、图像、音频等不同的模态可以像人类那样提供互补信息,正因为这样,其对于多模态上下文的学习能够更全面、细致地理解数据。
此外,还可以利用每种模态的优势,引导模型理解不同类型信息之间的交互。
在该研究中,全模态数据量达到 3 亿,模型预训练的整体规模达到 10 亿参数级别规模。
张懿元表示,在该范式作用下,大模型会整体变得更加通用和更加类人。未来的研究中,将争取得到更高的算力和更高效的算法等资源支持,并探索多模态的尺度规律,以发现更多突破的可能性。
MiCo 中多模态上下文预训练算法是 AI 模拟人脑多模态认知的一次重要尝试,未来有望基于此开发出更强大的全模态基础模型。
该课题组希望在下一个研究阶段中,将模型参数量提升 10 倍,以与主流使用的商用大模型进行比较和提升。
“希望能够早日开发出中国自研的商用大模型,这也是国际科技竞争中重要的一环。”他说。
参考资料:
1.https://arxiv.org/pdf/2406.09412
2.https://invictus717.github.io/MiCo/
3.https://github.com/invictus717/MiCo
排版:朵克斯